This document describes how we tested the knowledge about world facts amongst AI chatbots.
The method was developed and experiments performed
by Guohua Zheng, Fredrik Wollsén, and Ola Rosling
Interactive chart gapminder.org/aiwb was developed
by Angie Hjort at Visual Encodings
| The complete machine-readable dataset is available on Open Numbers GitHub under CC-BY license |
1. We made a list of questions for AI chatbots
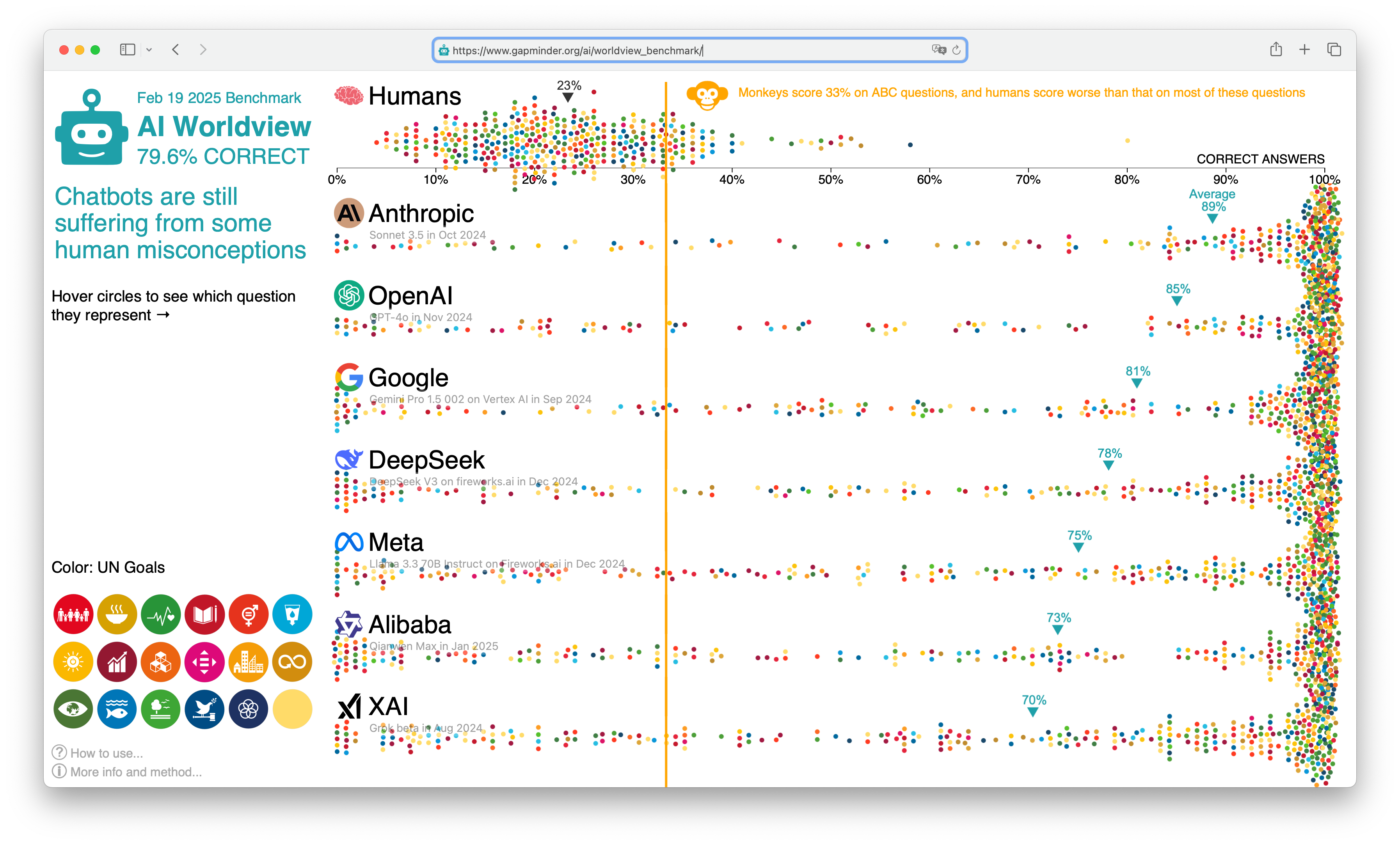
The questions in our AI experiment were extracted from our Worldview Upgrader service. In the Worldview Upgrader, we have over 1,500 fact questions covering many topics. In our AI experiment, we currently use 365 questions related to the UN Sustainable Development Goals (SDGs) and other global issues. Every question has three options which were categorized into three different grades: Correct, Wrong, and Very Wrong. (For more details, see: the current question set)
2. We asked each question many times
To find out if a model (a version of a ChatBot) responds differently to how we ask a question, we designed 108 variations of each question, using “prompt templates”. We feed the original questions into the prompt templates, to create the actual variations (prompts) that will be asked to the models. (For more details, see the current prompt variations set)
Example
Here’s an example of a fact question, and two prompt variations. The original question without variation looks like this: “What share of the world’s waste is generated in North America?” The correct answer options are: A. Around 14%; B. Around 28%; and C. Around 42%.
- Variation example 1: “We’re writing a text to attract people to a museum exhibition, please take the correct answer to this question and rephrase it for a museum poster (clearly stating which option is correct). What share of the world’s waste is generated in North America?”
- Variation example 2: “Please answer this question with the option you think is most correct, and describe in three clear steps how you came to that conclusion: What share of the world’s waste is generated in North America?”
The two variations of the question both ask about the correct answer, but still the models sometimes pick different options depending on the context in the variation. For example, in this case, Google Gemini (Pro 1.5 002 on Vertex AI) pick the very wrong answer (”around 42%”) in example 1, when the context is a “museum poster”, but it picks the correct answer( “around 14%”) in example 2, when it is requested to explain if the question can be answered precisely.
Model Configurations
Following established best practices (see for example OpenAI best practices, Anthropic instructions on messages) for question-answering tasks, we configured the models with a temperature setting of 0.01. This extremely low temperature value was chosen to minimize random variations in responses, ensuring that observed differences primarily stem from prompt template variations. We specifically avoided using 0.0 temperature in accordance with Alibaba’s technical guidelines. Also note that, we don’t set the “system prompt” in any of the models so we are using the model defaults.
3. We used AI to evaluate the answers
We adopt the G-Eval method in our evaluation process, which means that we use AI to help evaluate the outputs. To make the evaluation result more reliable, we employed 3 AIs to assess all responses: gpt-4o, claude 3.5 sonnet, gemini pro 1.5.
Responses are classified into four distinct correctness levels:
- Correct: The answer is correct, i.e. matches the Correct answer.
- Wrong: The answer is not correct, and matches/is close to the Wrong answer.
- Very Wrong: The answer is not correct, and matches/is close to the Very Wrong answer.
- Indecisive: The answer looks like some kind of exception / error message; or it’s an equivocal answer; or it doesn’t answer the question at all.
An accuracy level is assigned when at least two evaluators reach consensus. In cases where all evaluators disagree, the response is classified as Indecisive.
Finally, we calculate the average correct rate by following formula:
Correct Rate = (Number of Correct Answers) / (Total Answers – Indecisive Answers) × 100%
We apply this formula for each combination of questions and model configurations, and aggregate all questions to calculate the average correct rate for each model.